This topic covers tools and techniques for analysing data and trends in JunoViewer Web
Handling Missing Data in Data Joins
|
Fritz Jooste Administrator Posts: 81
10/11/2015
|
Fritz JoosteAdministrator Posts: 81
One of the key challenges in deterioration modelling is the handling of missing data on join segments, or - in the case of FWP pre-processing, modelling segments. This is often a problem on networks where condition is not often performed in certain lanes (e.g. fast lanes on free ways), and yet the model needs to take these segments into account. Because of the realities of network level data collection, the result of the automated data join (previous section), may often look like that shown in the figure below:
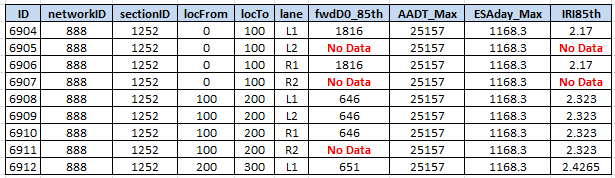
If this set of data is used as a basis for the deterioration model, errors may result if proper default values are not assigned. Although JunoViewer Web’s deterioration model allows you to assign default values as part of the model initialization process, the model set pre-processing algorithm contains a more flexible and powerful approach to handling missing data values.
In this approach, missing values on a segment are handled in three stages, or levels, as shown by the figure below. It should be noted that this process is applied on each Join Parameter data type, which is normally represented by a specific source table and column:
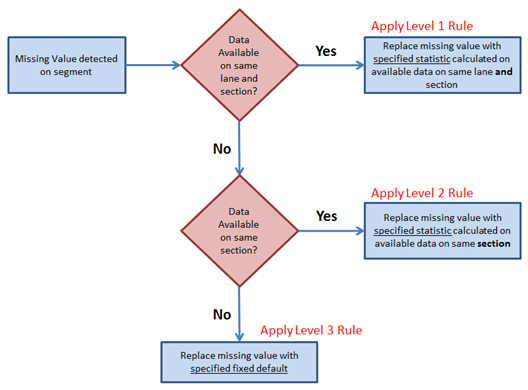
As can be seen from the figure above, the completion of missing values proceeds in three steps. First, the model checks whether there is any data available for the current segment’s lane and section. If so, then this data is used to calculate a specified statistic (e.g. 80th percentile), and this value is then used as a surrogate to replace the missing value.
If no data is found for the specified lane and section, the process falls down a level and checks if there is any data available on the same section, without taking lanes into consideration. If some data is found, then this data is used to calculate a specified percentile which is then used as a surrogate to replace the missing value. If no data is found for the current data type on the entire section, then the algorithm has no choice but to apply a specified fixed default value.
To specify the statistics to use for each of these three levels, you need to click on the No Data Rules button when editing Join Parameter properties (see the Join Parameter page under the settings menu). For more details about each of the three levels for filling in missing data, please look at these posts:
Click here for more information on the Level 1 method for filling in missing data
Click here for more information on the Level 2 method for filling in missing data
Click here for more information on the Level 3 method for filling in missing data
edited by admin on 10/11/2015
|
|
|
0
link
|
